
Machine-Learning-Based Method for Content-Adaptive Video Encoding
S. Zvezdakov, D. Kondranin, and D. Vatolin
Contact us:
Abstract
Video codecs have several dozen parameters that subtly affect the encoding rate, quality and size of the compressed video. Codec developers, as a rule, provide standard presets that on average yield acceptable performance for all videos, but for a given video, certain parameters may yield more efficient encoding. In this paper, we propose a new approach to predicting video codec presets to increase compression efficiency. Our effort involved collecting a new representative video-sequence dataset from Vimeo.com. An experimental evaluation showed relative bitrate decreases of 17.8% and 7.9%, respectively for the x264 and x265 codecs with standard options, all while maintaining quality and speed. Comparison with other methods revealed significantly faster automatic preset selection with a comparable improvement in results. Finally, our proposed content-adaptive method predicts presets that archive better performance than codec-developer presets from MSU Codec Comparison 2020 [1].
Key Features
- A new approach to predicting video codec presets to increase compression efficiency
- Predicted presets decrease bitrate of the x264 and x265 codecs by 17.8% and 7.9% compared to standard options
- Method is independent of the video codec’s architecture and implementation
Dataset
We create our dataset using the selection technique from “MSU Video Codecs Comparison 2016” [2], we have analyzed more than one million videos and downloaded 7,036 unique high bitrate videos from Vimeo.com and processed them further. Below you can see the bitrate distributions for our video dataset by year. You can also see SI/TI distribution of datasets.
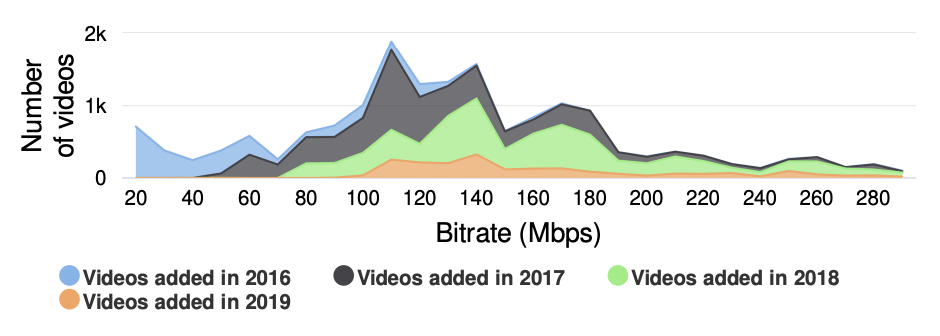
Bitrate distribution for videos downloaded from Vimeo.com.
Proposed method
The main idea of content-adaptive encoding (CAE) is to replace a reference preset (by which we encoded all previous video groups) with other presets that will more efficiently encode an input video. We can formulate CAE for video V using Eq. 1, where P is the set of all possible presets, S - the relative encoding speed, Q - the relative bitrate.
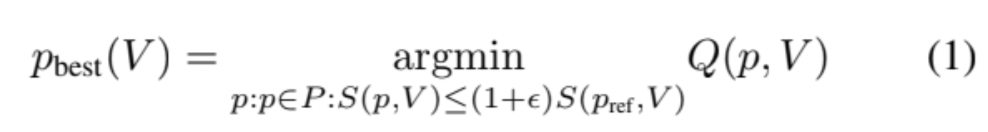
Solving this problem is a time-consuming task. Therefore, we decided to replace the regression problem with a classification problem. Our proposed method aims to solve the classification problem for each video and reference preset: the model must select one of several presets. We assume it is possible to improve on the reference preset by choosing from a few predefined presets. Formally, this problem requires finding presets p1, …, pk for a set of videos H and for each k such that:
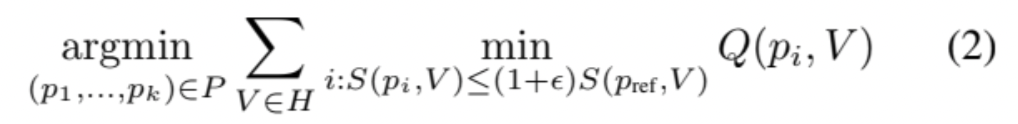
Comparison of proposed method with the best possible improvement for x265 and x264 using created dataset.
| x265 | ultrafast | superfast | veryfast | faster | fast | medium | slow | slower | veryslow | placebo |
| Proposed | 11.83% | 15.60% | 3.75% | 3.59% | 2.78% | 1.64% | 7.86% | 10.04% | 8.76% | 8.59% |
| Proposed, custom loss | 12.09% | 15.82% | 3.82% | 3.73% | 4.69% | 1.77% | 8.60% | 10.36% | 9.28% | 9.04% |
| Best (in our dataset) | 14.66% | 18.40% | 6.49% | 6.38% | 6.44% | 6.38% | 11.67% | 12.31% | 11.88% | 11.47% |
For x265 with the
faster preset, our method can reduce the file size by 3.73%.
The proposed loss function in some cases enables a further 1-2% reduction.
| x264 | ultrafast | superfast | veryfast | faster | fast | medium | slow | slower | veryslow | placebo |
| Proposed | 71.86% | 14.18% | 8.63% | 12.65% | 12.80% | 11.91% | 9.88% | 12.69% | 9.93% | 10.00% |
| Proposed, custom loss | 72.74% | 14.18% | 9.80% | 13.05% | 13.55% | 12.81% | 9.54% | 12.88% | 9.85% | 9.85% |
| Best (in our dataset) | 73.72% | 19.73% | 13.73% | 17.58% | 18.50% | 16.40% | 13.69% | 15.99% | 13.68% | 13.36% |
For x264, we achieved a much greater improvement relative to the reference presets. Given the slower preset, the filesize decrease is 12.88%. Moreover, given the placebo preset, the encoding time decreased by 68.09% when the file size decreased by 9.85%.
Comparison with other methods
We compared our method with analogs. Here you can see average bitrate savings of the Pareto optimal
presets versus standard presets, along with execution time for
each method using dataset from [3] (351 video, x264).
| Preset | Popov[4] | NSGA-II[5] | Zvezdakov[6] | Kazantsev[3] | Proposed |
| faster | 8.0% | 15.9% | 11.0% | 15.8% | 3.0% |
| fast | 29.0% | 30.2% | 30.2% | 21.3% | 28.6% |
| medium | 28.4% | 29.7% | 29.8% | 21.8% | 29.8% |
| slow | 34.9% | 34.9% | 34.9% | 27.7% | 35.0% |
| slower | 32.2% | 32.2% | 32.2% | 24.9% | 32.7% |
| veryslow | 28.3% | 29.0% | 28.7% | 9.7% | 28.9% |
| placebo | 29.0% | 28.3% | 29.4% | 10.5% | 29.5% |
| Time | 2.78 h. | 3.8 h. | 2.14 h. | 735.5 s. | 468.4 s. |
More detailed comparison results: comparison results on JCT-VC and xiph.org datasets.
Cite us
@INPROCEEDINGS{9477507,
author={Zvezdakov, Sergey and Kondranin, Denis and Vatolin, Dmitriy},
booktitle={2021 Picture Coding Symposium (PCS)},
title={Machine-Learning-Based Method for Content-Adaptive Video Encoding},
year={2021},
volume={},
number={},
pages={1-5},
doi={10.1109/PCS50896.2021.9477507}}See also
- MSU Video Codecs Comparisons
- Machine-Learning-Based Method for Finding Optimal Video-Codec Configurations Using Physical Input-Video Features
References
[1] D. Kulikov, M. Erofeev, A. Antsiferova, E. Sklyarov, A. Yakovenko, and N. Safonov. HEVC/AV1 Video Codecs Comparison 2020. Dec 07, 2020.
[2] D. Vatolin, D. Kulikov, M. Erofeev, S. Dolganov, and S. Zvezdakov. Eleventh MSU Video Codecs Comparison. Aug 22, 2016.
[3] R. Kazantsev, S. Zvezdakov, and D. Vatolin, “Machine-learning-based
method for finding optimal video-codec configurations using physical
input-video features,” in 2020 Data Compression Conference (DCC).
IEEE, 2020, pp. 374–374.
[4] V. Popov, “Automatic method of choosing pareto optimal video codec’s
parameters,” Master’s thesis, Lomonosov Moscow State University,
2009.
[5] K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, “A fast and elitist
multiobjective genetic algorithm: Nsga-ii,” IEEE transactions on evolu-
tionary computation, vol. 6, no. 2, pp. 182–197, 2002.
[6] S. V. Zvezdakov and D. S. Vatolin, “Building a x264 video codec
model,” in Innovative technologies in cinema and education: IV
International Symposium. VGIK Moscow, 2017, pp. 56–65.